Large Language Models with Temporal Reasoning for Longitudinal Clinical Summarization and Prediction
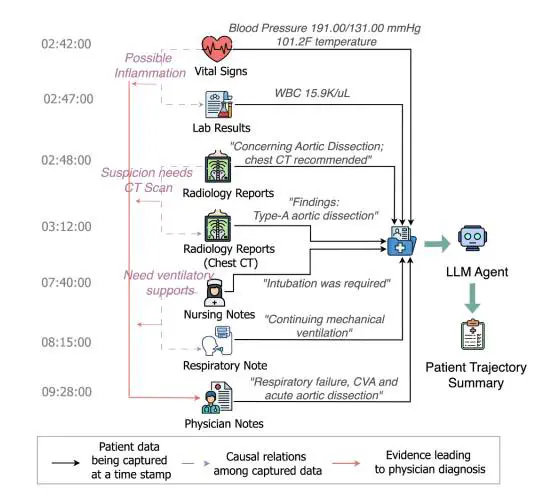 An illustration of the longitudinal patient trajectory summarization process from multi-modal EHRs.
An illustration of the longitudinal patient trajectory summarization process from multi-modal EHRs.Abstract
Recent advances in large language models (LLMs) have shown potential in clinical text summarization, but their ability to handle long patient trajectories with multi-modal data spread across time remains underexplored. This study systematically evaluates several state-of-the-art open-source LLMs, their Retrieval Augmented Generation (RAG) variants and chain-of-thought (CoT) prompting on long-context clinical summarization and prediction. We examine their ability to synthesize structured and unstructured Electronic Health Records (EHR) data while reasoning over temporal coherence, by re-engineering existing tasks, including discharge summarization and diagnosis prediction from two publicly available EHR datasets. Our results indicate that long context windows improve input integration but do not consistently enhance clinical reasoning, and LLMs are still struggling with temporal progression and rare disease prediction. While RAG shows improvements in hallucination in some cases, it does not fully address these limitations. Our work fills the gap in long clinical text summarization, establishing a foundation for evaluating LLMs with multi-modal data and temporal reasoning.
This work takes on a pressing challenge in clinical AI: handling longitudinal patient trajectories (structured + unstructured EHR data across time) for summarization and prediction tasks using LLMs. The authors evaluate several open‐source LLMs (and their Retrieval-Augmented Generation (RAG) variants and chain-of-thought prompting) on re‐engineered tasks from two public EHR datasets.
Key findings:
- Using long context windows (i.e., more of the patient history) does help input integration (i.e., the model sees more data) but does not consistently improve clinical reasoning.
- LLMs continue to struggle with temporal progression (i.e., reasoning about changes over time). Use of RAG led to some improvements in reducing hallucination, but did not fully fix the temporal or rare‐disease limitations.
- The study thus establishes a benchmark/evaluation foundation for “LLMs + multi-modal long clinical text + temporal reasoning” — an important domain gap.
Why does this matter for our lab?
- Very aligned with our work: we’re focused on diagnostic AI in critical care, dealing with EHRs, sequential annotation, temporal progression, and uncertainty. This paper addresses precisely those pain points: lengthy clinical documents, temporal reasoning, and rare conditions.
- The finding that more context doesn’t automatically yield better reasoning is crucial — it alerts us to avoid the “context window = silver bullet” assumption.
- The use of RAG and chain‐of‐thought in a clinical setting highlights what methods already exist — and where they fall short — providing a clearer roadmap for where we might innovate (e.g., multi-agent LLMs, uncertainty calibration, mechanistic bias analysis).