Advancing Trustworthy LLM Summarization in Clinical Domains -- Current State, A Novel Instrument, and LLM-as-a-Judge
How Do We Know a Clinical Summary is Good?
Having spent years working on summarization evaluation in my PhD (before LLM era), I know just how hard it is: There is no single “correct” summary—different summaries may emphasize different relevant points, and human judgment varies. The challenge is compounded by knowledge gaps, reasoning variability, and human biases.
In high-stakes domains like healthcare, a “pretty good” summary isn’t good enough. When clinical decisions hinge on what a large language model (LLM) chooses to summarize—or omit—rigorous, trustworthy evaluation is essential.
At LARK Lab, we’ve been tackling this challenge head-on through a series of studies focused on evaluating LLM-generated clinical text summaries. Clinical summarization isn’t just about fluency or coherence. It’s about aligning with physician reasoning, avoiding hallucinations, and reflecting the complexity of patient care.
To address this, we have launched a three-part research program:
🔍 **1. Current State-of-the-art in Clinical Summarization Evaluation **
We began by systematically examining the state of LLM summarization evaluation, both traditional metrics like ROUGE and BERTScore, and alignment-based methods involving human preference. Our analysis revealed deep limitations in current metrics when applied to clinical text, where factual correctness and clinical relevance are non-negotiable. Our paper has been published in npj Health System Paper.
🧪 2. Developing PDQSI-9: A Validated Clinical Evaluation Instrument
Next, we designed PDQSI-9, an evaluation instrument rooted in clinical expertise. We validated the instrument through an expert study involving multiple physicians reviewing AI-generated summaries. Remarkably, despite differences in specialty and background, physicians reached high inter-rater agreement (ICC) using PDQSI-9—demonstrating that expert consensus on summary quality is achievable when grounded in the right framework. Our paper is published on Journal of American Medical Informatics Association Paper.
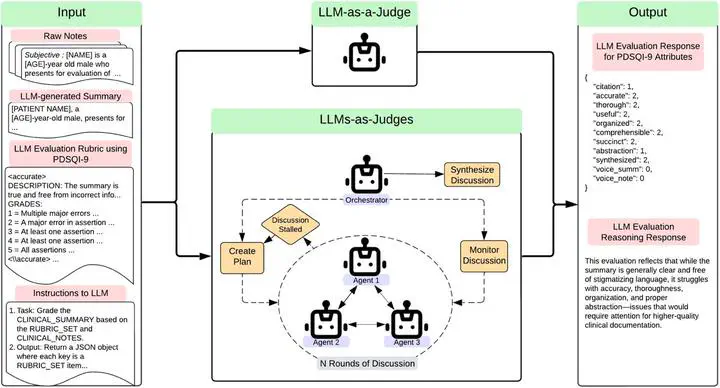
🤖 3. Training LLM-as-a-Judge with Multi-Agent Learning
In our latest work, we are exploring whether LLMs can mimic human evaluation using PDQSI-9 as supervision. We developed a multi-agent, LLM-as-a-judge framework, training models to align their judgments with those of physicians. Early results are promising—suggesting that LLMs, when properly guided, can learn to identify clinically sound summaries with a degree of consistency close to human experts. Preprint
Together, these studies mark meaningful progress toward making AI-generated clinical summaries reliable, interpretable, and clinically safe. We’re proud to be contributing to this essential area, and excited to share more as we continue building the foundations for trustworthy clinical NLP.
This is a collaboration effort with ICU Data Science Lab at University of Wisconsin Madison (shout out to Emma Croxford, a PhD student at UW Department of Biostatistics and Medical Informatics, and Dr. Majid Afshar, the PI at UWisc lab and leader in this field), Epic System and UW Health.
Stay tuned for preprints, code releases, and upcoming talks!